https://medium.com/@ademolajhon/how-to-clone-a-website-with-httrack-on-mac-fcbd935ccdc4
How to Clone a Website with Httrack on Mac
I know you might have searched the internet on how to clone a website with your mac but you have not found a good article on that. I believe this will teach you how to do this with easy steps
We are going to be using Httrack.
- Find a website that you want to clone
- Press
Command+Spaceand type *Terminal* and press *enter/return* key. - Type this command on the Terminal:
*and press *enter/return* key. If the screen prompts you to enter a password, please enter your Mac’s user password to continue. When you type the password, it won’t be displayed on screen, but the system would accept it. So just type your password and press ENTER/RETURN key. Then wait for the command to finish.ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" < /dev/null 2> /dev/null - Type this command on the Terminal:
wait for it httrack to download in this folder “/usr/local/Cellar/httrack/” To go to that folder you can right click on “Finder” and click “Go to Folder” and input the path (“/usr/local/Cellar/httrack/”)**brew install httrack - Go into the folder named bin under the folder named the version of httrack downloaded. As at the time of this tutorial, mine is 3.49.2_1 This is the full path “/usr/local/Cellar/httrack/3.49.2_1/bin”
- Open the terminal called “httrack”. You should have a Terminal like the image below
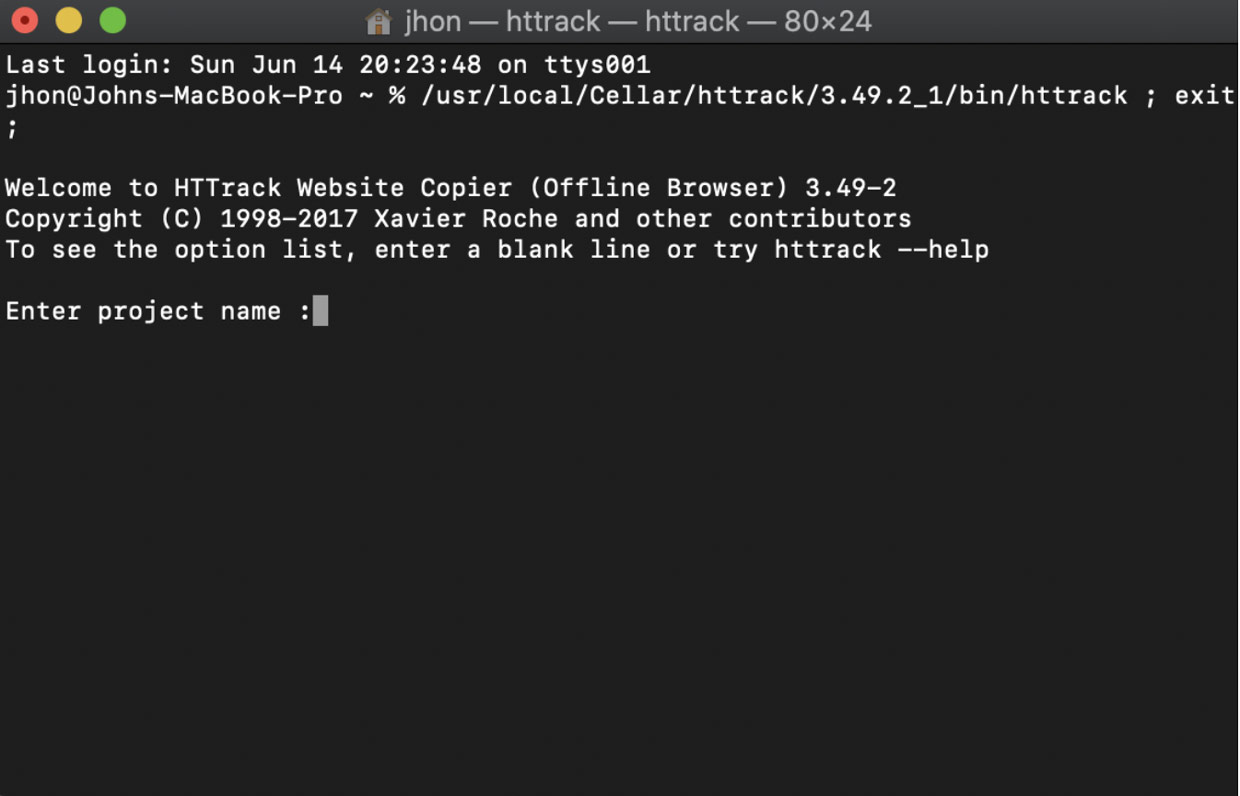
7. Enter your desired project name and click enter/return
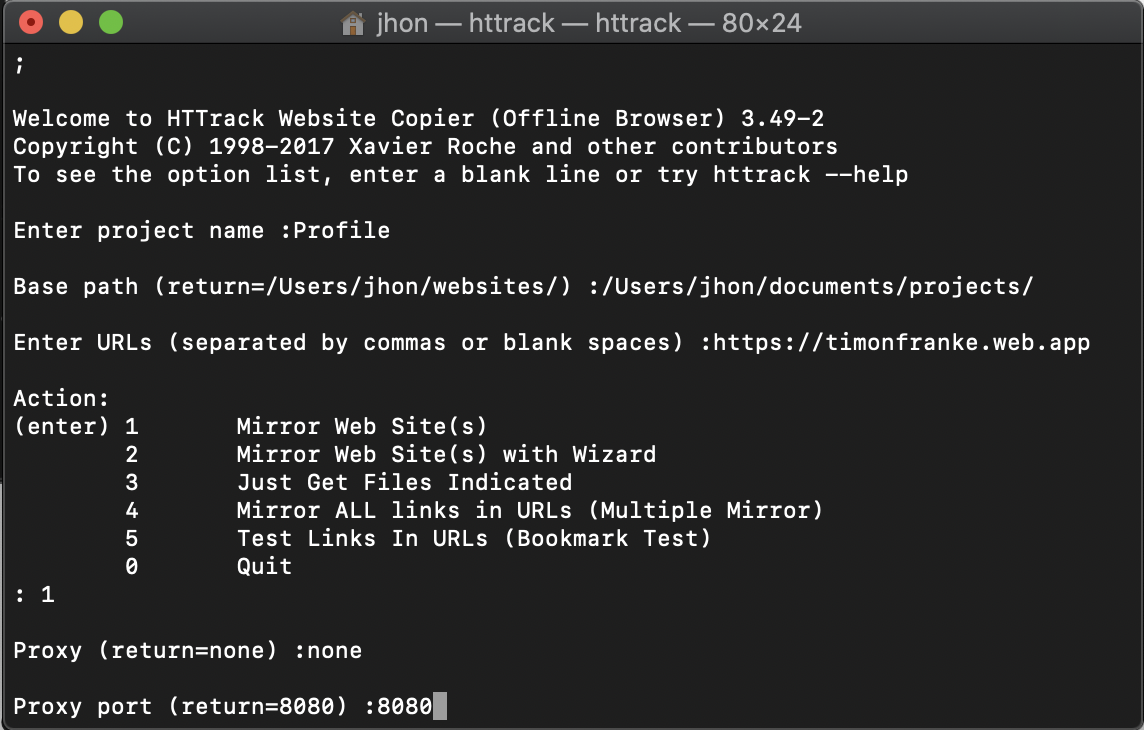
8. Enter the Base path you want to save the files to and click enter/return
8. Enter the website url you want to clone and click enter/return
9. Type the number related to “Mirror web site(s) and click enter/return. The number related to mine is 1. like the image below
![]()

10. Type none for Proxy and click enter/return
11. Type the port number in the parenthesis and click enter/return. Mine is 8080 like in the image below
![]()
12. Type none for wildcards and click enter/return
13. Type none for Additional options and click enter/return
14. Type “Y” for Ready to launch the mirror? and click enter/return
15. Wait about 2–10 minutes for the files to clone successfully!

Httrack – Options List
General options:
O path for mirror/logfiles+cache (-O path_mirror[,path_cache_and_logfiles]) (–path )
Action options:
w *mirror web sites (–mirror)
W mirror web sites, semi-automatic (asks questions) (–mirror-wizard)
g just get files (saved in the current directory) (–get-files)
i continue an interrupted mirror using the cache (–continue)
Y mirror ALL links located in the first level pages (mirror links) (–mirrorlinks)
Proxy options:
P proxy use (-P proxy:port or -P user:pass@proxy:port) (–proxy )
%f *use proxy for ftp (f0 don't use) (–httpproxy-ftp[=N])
%b use this local hostname to make/send requests (-%b hostname) (–bind )
Limits options:
rN set the mirror depth to N (* r9999) (–depth[=N])
%eN set the external links depth to N (* %e0) (–ext-depth[=N])
mN maximum file length for a non-html file (–max-files[=N])
mN,N2 maximum file length for non html (N) and html (N2)
MN maximum overall size that can be uploaded/scanned (–max-size[=N])
EN maximum mirror time in seconds (60=1 minute, 3600=1 hour) (–max-time[=N])
AN maximum transfer rate in bytes/seconds (1000=1KB/s max) (–max-rate[=N])
%cN maximum number of connections/seconds (*%c10) (–connection-per-second[=N])
GN pause transfer if N bytes reached, and wait until lock file is deleted (–max-pause[=N])
Flow control:
cN number of multiple connections (*c8) (–sockets[=N])
TN timeout, number of seconds after a non-responding link is shutdown (–timeout[=N])
RN number of retries, in case of timeout or non-fatal errors (*R1) (–retries[=N])
JN traffic jam control, minimum transfert rate (bytes/seconds) tolerated for a link (–min-rate[=N])
HN host is abandonned if: 0=never, 1=timeout, 2=slow, 3=timeout or slow (–host-control[=N])
Links options:
%P *extended parsing, attempt to parse all links, even in unknown tags or Javascript (%P0 don't use) (–extended-parsing[=N])
n get non-html files 'near' an html file (ex: an image located outside) (–near)
t test all URLs (even forbidden ones) (–test)
%L
%S
Build options:
NN structure type (0 *original structure, 1+: see below) (–structure[=N])
or user defined structure (-N "%h%p/%n%q.%t")
%N delayed type check, don't make any link test but wait for files download to start instead (experimental) (%N0 don't use, %N1 use for unknown extensions, * %N2 always use)
%D cached delayed type check, don't wait for remote type during updates, to speedup them (%D0 wait, * %D1 don't wait) (–cached-delayed-type-check)
%M generate a RFC MIME-encapsulated full-archive (.mht) (–mime-html)
LN long names (L1 *long names / L0 8-3 conversion / L2 ISO9660 compatible) (–long-names[=N])
KN keep original links (e.g. http://www.adr/link) (K0 *relative link, K absolute links, K4 original links, K3 absolute URI links, K5 transparent proxy link) (–keep-links[=N])
x replace external html links by error pages (–replace-external)
%x do not include any password for external password protected websites (%x0 include) (–disable-passwords)
%q *include query string for local files (useless, for information purpose only) (%q0 don't include) (–include-query-string)
o *generate output html file in case of error (404..) (o0 don't generate) (–generate-errors)
X *purge old files after update (X0 keep delete) (–purge-old[=N])
%p preserve html files 'as is' (identical to '-K4 -%F ""') (–preserve)
%T links conversion to UTF-8 (–utf8-conversion)
Spider options:
bN accept cookies in cookies.txt (0=do not accept,* 1=accept) (–cookies[=N])
u check document type if unknown (cgi,asp..) (u0 don't check, * u1 check but /, u2 check always) (–check-type[=N])
j *parse Java Classes (j0 don't parse, bitmask: |1 parse default, |2 don't parse .class |4 don't parse .js |8 don't be aggressive) (–parse-java[=N])
sN follow robots.txt and meta robots tags (0=never,1=sometimes,* 2=always, 3=always (even strict rules)) (–robots[=N])
%h force HTTP/1.0 requests (reduce update features, only for old servers or proxies) (–http-10)
%k use keep-alive if possible, greately reducing latency for small files and test requests (%k0 don't use) (–keep-alive)
%B tolerant requests (accept bogus responses on some servers, but not standard!) (–tolerant)
%s update hacks: various hacks to limit re-transfers when updating (identical size, bogus response..) (–updatehack)
%u url hacks: various hacks to limit duplicate URLs (strip //, http://www.foo.com==foo.com..) (–urlhack)
%A assume that a type (cgi,asp..) is always linked with a mime type (-%A php3,cgi=text/html;dat,bin=application/x-zip) (–assume )
shortcut: '–assume standard' is equivalent to -%A php2 php3 php4 php cgi asp jsp pl cfm nsf=text/html
can also be used to force a specific file type: –assume foo.cgi=text/html
@iN internet protocol (0=both ipv6+ipv4, 4=ipv4 only, 6=ipv6 only) (–protocol[=N])
%w disable a specific external mime module (-%w htsswf -%w htsjava) (–disable-module )
Browser ID:
F user-agent field sent in HTTP headers (-F "user-agent name") (–user-agent )
%R default referer field sent in HTTP headers (–referer )
%E from email address sent in HTTP headers (–from )
%F footer string in Html code (-%F "Mirrored [from host %s [file %s [at %s]]]" (–footer )
%l preffered language (-%l "fr, en, jp, *" (–language )
%a accepted formats (-%a "text/html,image/png;q=0.9,/;q=0.1" (–accept )
%X additional HTTP header line (-%X "X-Magic: 42" (–headers )
Log, index, cache
C create/use a cache for updates and retries (C0 no cache,C1 cache is prioritary,* C2 test update before) (–cache[=N])
k store all files in cache (not useful if files on disk) (–store-all-in-cache)
%n do not re-download locally erased files (–do-not-recatch)
%v display on screen filenames downloaded (in realtime) – * %v1 short version – %v2 full animation (–display)
Q no log – quiet mode (–do-not-log)
q no questions – quiet mode (–quiet)
z log – extra infos (–extra-log)
Z log – debug (–debug-log)
v log on screen (–verbose)
f *log in files (–file-log)
f2 one single log file (–single-log)
I *make an index (I0 don't make) (–index)
%i make a top index for a project folder (* %i0 don't make) (–build-top-index)
%I make an searchable index for this mirror (* %I0 don't make) (–search-index)
Expert options:
pN priority mode: (* p3) (–priority[=N])
p0 just scan, don't save anything (for checking links)
p1 save only html files
p2 save only non html files
*p3 save all files
p7 get html files before, then treat other files
S stay on the same directory (–stay-on-same-dir)
D *can only go down into subdirs (–can-go-down)
U can only go to upper directories (–can-go-up)
B can both go up&down into the directory structure (–can-go-up-and-down)
a *stay on the same address (–stay-on-same-address)
d stay on the same principal domain (–stay-on-same-domain)
l stay on the same TLD (eg: .com) (–stay-on-same-tld)
e go everywhere on the web (–go-everywhere)
%H debug HTTP headers in logfile (–debug-headers)
Guru options: (do NOT use if possible)
#X *use optimized engine (limited memory boundary checks) (–fast-engine)
#0 filter test (-#0 '*.gif' 'http://www.bar.com/foo.gif') (–debug-testfilters )
#1 simplify test (-#1 ./foo/bar/../foobar)
#2 type test (-#2 /foo/bar.php)
#C cache list (-#C '.com/spider.gif' (–debug-cache )
#R cache repair (damaged cache) (–repair-cache)
#d debug parser (–debug-parsing)
#E extract new.zip cache meta-data in meta.zip
#f always flush log files (–advanced-flushlogs)
#FN maximum number of filters (–advanced-maxfilters[=N])
#h version info (–version)
#K scan stdin (debug) (–debug-scanstdin)
#L maximum number of links (-#L1000000) (–advanced-maxlinks[=N])
#p display ugly progress information (–advanced-progressinfo)
#P catch URL (–catch-url)
#R old FTP routines (debug) (–repair-cache)
#T generate transfer ops. log every minutes (–debug-xfrstats)
#u wait time (–advanced-wait)
#Z generate transfer rate statictics every minutes (–debug-ratestats)
Dangerous options: (do NOT use unless you exactly know what you are doing)
%! bypass built-in security limits aimed to avoid bandwidth abuses (bandwidth, simultaneous connections) (–disable-security-limits)
IMPORTANT NOTE: DANGEROUS OPTION, ONLY SUITABLE FOR EXPERTS
USE IT WITH EXTREME CARE
Command-line specific options:
V execute system command after each files ($0 is the filename: -V "rm $0") (–userdef-cmd )
%W use an external library function as a wrapper (-%W myfoo.so[,myparameters]) (–callback )
Details: Option N
N0 Site-structure (default)
N1 HTML in web/, images/other files in web/images/
N2 HTML in web/HTML, images/other in web/images
N3 HTML in web/, images/other in web/
N4 HTML in web/, images/other in web/xxx, where xxx is the file extension (all gif will be placed onto web/gif, for example)
N5 Images/other in web/xxx and HTML in web/HTML
N99 All files in web/, with random names (gadget !)
N100 Site-structure, without http://www.domain.xxx/
N101 Identical to N1 exept that "web" is replaced by the site's name
N102 Identical to N2 exept that "web" is replaced by the site's name
N103 Identical to N3 exept that "web" is replaced by the site's name
N104 Identical to N4 exept that "web" is replaced by the site's name
N105 Identical to N5 exept that "web" is replaced by the site's name
N199 Identical to N99 exept that "web" is replaced by the site's name
N1001 Identical to N1 exept that there is no "web" directory
N1002 Identical to N2 exept that there is no "web" directory
N1003 Identical to N3 exept that there is no "web" directory (option set for g option)
N1004 Identical to N4 exept that there is no "web" directory
N1005 Identical to N5 exept that there is no "web" directory
N1099 Identical to N99 exept that there is no "web" directory
Details: User-defined option N
'%n' Name of file without file type (ex: image)
'%N' Name of file, including file type (ex: image.gif)
'%t' File type (ex: gif)
'%p' Path [without ending /] (ex: /someimages)
'%h' Host name (ex: http://www.someweb.com)
'%M' URL MD5 (128 bits, 32 ascii bytes)
'%Q' query string MD5 (128 bits, 32 ascii bytes)
'%k' full query string
'%r' protocol name (ex: http)
'%q' small query string MD5 (16 bits, 4 ascii bytes)
'%s?' Short name version (ex: %sN)
'%[param]' param variable in query string
'%[param:before:after:empty:notfound]' advanced variable extraction
Details: User-defined option N and advanced variable extraction
%[param:before:after:empty:notfound]
param : parameter name
before : string to prepend if the parameter was found
after : string to append if the parameter was found
notfound : string replacement if the parameter could not be found
empty : string replacement if the parameter was empty
all fields, except the first one (the parameter name), can be empty
Details: Option K
K0 foo.cgi?q=45 -> foo4B54.html?q=45 (relative URI, default)
K -> http://www.foobar.com/folder/foo.cgi?q=45 (absolute URL) (–keep-links[=N])
K3 -> /folder/foo.cgi?q=45 (absolute URI)
K4 -> foo.cgi?q=45 (original URL)
K5 -> http://www.foobar.com/folder/foo4B54.html?q=45 (transparent proxy URL)
Shortcuts:
–mirror
–get
–list
–mirrorlinks
–testlinks
–spider
–testsite
–skeleton
–update update a mirror, without confirmation (-iC2)
–continue continue a mirror, without confirmation (-iC1)
–catchurl create a temporary proxy to capture an URL or a form post URL
–clean erase cache & log files
–http10 force http/1.0 requests (-%h)
Details: Option %W: External callbacks prototypes
see htsdefines.h
example: httrack http://www.someweb.com/bob/
means: mirror site http://www.someweb.com/bob/ and only this site
example: httrack http://www.someweb.com/bob/ http://www.anothertest.com/mike/ +.com/.jpg -mime:application/*
means: mirror the two sites together (with shared links) and accept any .jpg files on .com sites
example: httrack http://www.someweb.com/bob/bobby.html +* -r6
means get all files starting from bobby.html, with 6 link-depth, and possibility of going everywhere on the web
example: httrack http://www.someweb.com/bob/bobby.html –spider -P proxy.myhost.com:8080
runs the spider on http://www.someweb.com/bob/bobby.html using a proxy
example: httrack –update
updates a mirror in the current folder
example: httrack
will bring you to the interactive mode
example: httrack –continue
continues a mirror in the current folder
HTTrack version 3.49-2
Copyright (C) 1998-2017 Xavier Roche and other contributors
You can define additional options, such as recurse level (-r
To see the option list, type help
Additional options (return=none) :